

I calcoli, che siano per un’analisi strutturale o fluidodinamica, richiedono un dispendio di tempo e di risorse non indifferente. Negli ultimi anni, si stanno diffondendo sempre più strumenti alternativi che possono predire il risultato di un’analisi in pochissimi secondi e con un dispendio di risorse decisamente minore: modelli di ordine ridotto, superfici surrogate, e negli ultimi anni anche Machine Learning e AI.
L’attività di progettazione, almeno nelle aziende più strutturate, prosegue in parallelo con l’attività di calcolo predittivo delle performance del progetto.
Mentre in passato ci si affidava spesso all’esperienza del progettista e all’utilizzo di diversi prototipi, la richiesta della riduzione dei tempi di progettazione ha reso necessaria l’adozione di diverse forme di analisi che vengono effettuate su prototipi virtuali.
Il progettista può quindi già comprendere se la sua creazione rispetterà le performance richieste e in caso di esito negativo dell’analisi, come e dover modificare il suo progetto.
Purtroppo, però, sovente queste analisi risultano richiedere delle tempistiche piuttosto lunghe (un calcolo FEM semplice richiede al minimo un paio di giorni, uno CFD anche una settimana), tempo durante il quale il progettista rimane fermo. Inoltre, molto spesso, per queste analisi ci si deve affidare a consulenti esterni, con quindi anche notevole dispendio di risorse per le comunicazioni e possibili fraintendimenti.
Per questo motivo, negli ultimi anni si sono studiati dei metodi per velocizzare i calcoli, a scapito di una leggera perdita di accuratezza, non necessaria però nelle prime fasi di progettazione. Inoltre, per usare questi strumenti a volte non è richiesta una conoscenza approfondita delle tecniche di modellazione più avanzate.
Possiamo dividere questi strumenti in 3 macro categorie:
- analisi con fisica semplificata
- modelli predittivi basati su interpolazioni o superfici surrogate
- modelli predittivi basati su machine learning e intelligenza artificiale.
Reduced Order Models o “simulazioni real-time”
La prima categoria si basa sull’approssimazione della modellizzazione della fisica o della geometria. Per questo tipo di analisi, è generalmente necessario comunque disegnare una geometria da testare. In questo gruppo di strumenti possiamo includere i “Reduced Order Models” e le cosiddette “simulazioni real-time”.
Il primo si basa sulla riduzione la complessità della fisica analizzata, modellandone una lievemente approssimata. Per esempio, nelle analisi CFD è possibile sostituire le equazioni di Navier-Stokes con equazioni approssimate al primo ordine.
Il modello ROM utilizza quindi una rappresentazione più semplice della fisica completa, utilizzando un numero ridotto di parametri. Grazie a tecniche di modellizzazione più avanzate, si può comprender quali sono i parametri fisici più influenti e trascurare gli altri. È per esempio anche possibile approssimare un flusso 3D in uno 2D, sia per tutto il dominio di calcolo che per alcune zone particolari, risparmiando quindi di dover calcolare una o più equazioni.
Questo tipo di tecnica in realtà viene utilizzata già dai esperti analisti quando per esempio scelgono di approssimare un fluido reale con un fluido incomprimibile o un considerando un materiale perfettamente elastico e trascurando lo snervamento. I ROM ovviamente effettuano queste e ulteriori semplificazioni in maniera automatica.
La seconda tecnica si basa sulla semplificazione della rappresentazione della geometria, in particolare della griglia di calcolo. Al posto di risolvere le equazioni in una grande quantità di celle di mesh (si parla dell’ordine dei milioni per una simulazione CFD), si può approssimare la griglia di calcolo attraverso l’uso di un numero ridotto di voxels.
Esso è molto simile a un tetraedro utilizzato nelle mesh tradizionali, ma la sua creazione richiede un tempo di calcolo decisamente più ridotto (ordine di pochi minuti rispetto a ore per una mesh tradizionale) a scapito dell’accuratezza geometrica. D’altra parte, non ha senso rappresentare perfettamente una geometria sulla quale si hanno ancora molte incertezze.
Ciò significa però che le simulazioni basate su voxel potrebbero non essere altrettanto accurate quanto quelle basate su mesh, ma per fisiche semplici e soprattutto per geometrie non troppo complesse, l’errore nella simulazione è comunque contenuto in un 10-15%, valori alti ovviamente nelle fasi finali di progettazione, ma che possono servire al progettista in fase preliminare per avere un’idea delle performance del suo prodotto, in particolare, in caso di analisi comparative.
Come nel caso precedente, l’idea di approssimare la griglia di calcolo deriva dalla tecnica usata dagli analisti di effettuare delle analisi preliminari con mesh piuttosto rade per verificarne il corretto settaggio prima di effettuare l’analisi definitiva su mesh più fitte.

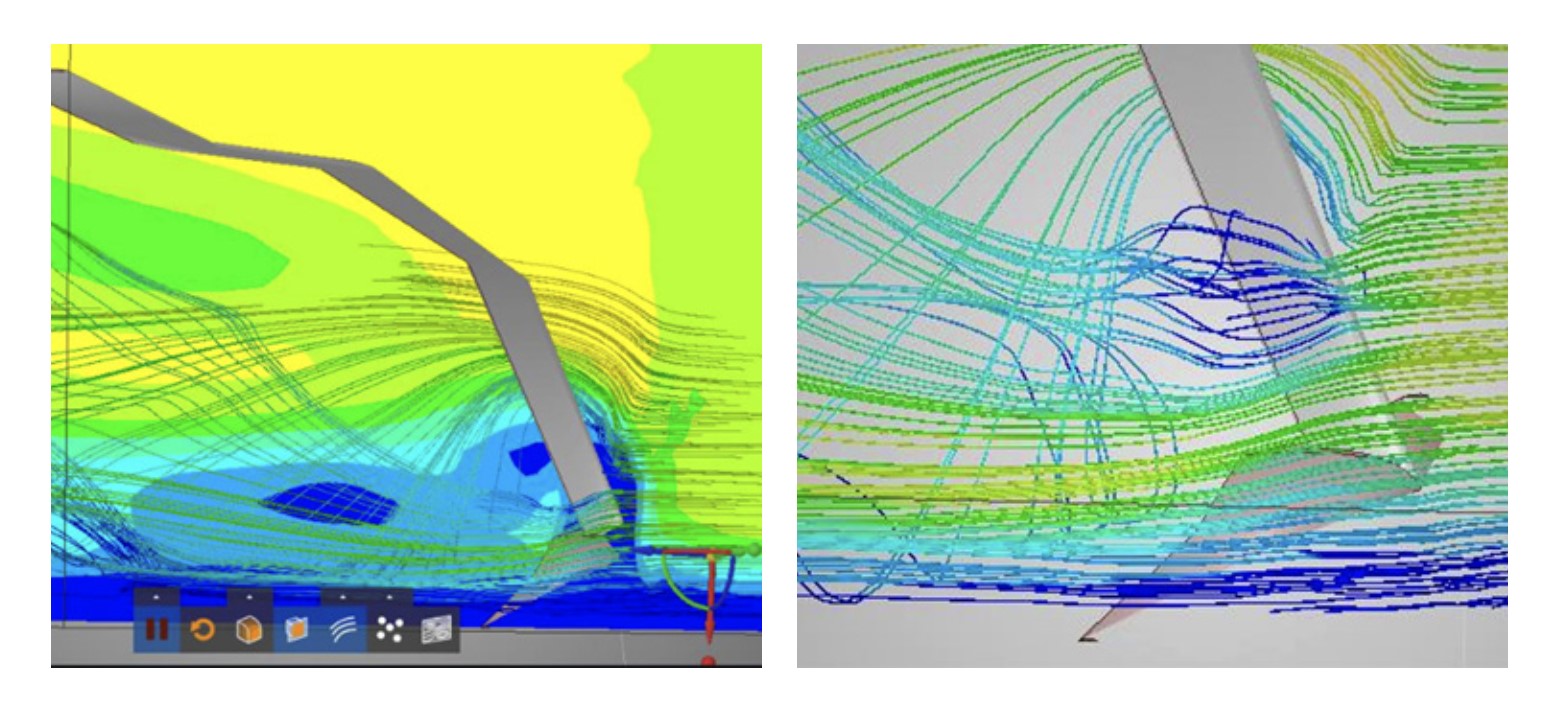
Modelli predittivi
I metodi appena descritti, pur geniali nella loro elaborazione, basano la riduzione delle tempistiche di calcolo sulla semplificazione del calcolo stesso, ma richiedono comunque la creazione di una geometria e l’effettuazione del calcolo.
I modelli predittivi, invece, fondano la loro velocità di elaborazione del calcolo soprattutto sui dati ottenuti da calcoli precedenti, senza dover effettuare nuove analisi. L’idea di fondo è quella che si possa estrapolare il risultato di una nuova geometria studiando quelli di quelle già analizzate, addirittura senza disegnarne una nuova.
Anche in questo caso, si tratta dell’elaborazione e formulazione scientifica di tecniche già utilizzate dagli ingegneri, ma da persone comuni nella vita di tutti i giorni: l’interpolazione ed estrapolazione.
L’interpolazione è un metodo matematico che utilizza informazioni conosciute (in questo caso, le analisi svolte su geometrie simili) per stimare valori sconosciuti, attraverso una funziona matematica. Essa viene utilizzata per determinare un valore approssimativo di un punto che si trova all’interno (all’esterno nel caso di estrapolazione) di una serie di dati. La scelta da dover effettuare è quella del tipo di interpolazione da utilizzare. La più semplice e quella che richiede un numero minimo di dati è quella di tipo lineare, ma è possibile anche utilizzare altre tipologie ben più complesse.
Ovviamente, per avere dei risultati molto vicini a quelli reali, è fondamentale la scelta del tipo di interpolazione. Fra i vari criteri, possiamo elencare:
- Il numero di punti noti: se ci sono solo pochi punti noti, potrebbe essere necessario utilizzare un metodo di interpolazione semplice come l’interpolazione lineare o polinomiale. La variazione fra 2 soli punti può essere approssimata solo attraverso una retta, fra 3 con una parabola e via dicendo.
- Conoscenza della funzione sottostante: se la funzione sottostante che descrive i dati è conosciuta, potrebbe essere possibile utilizzare un metodo di interpolazione specifico per quella funzione. Alcuni comportamenti fisici, infatti, si possono comunque stimare. Si sa che la resistenza aerodinamica di un corpo varia circa linearmente con l’area, mentre parabolicamente con la velocità. Il momento di inerzia di una struttura dipende linearmente dalla massa e parabolicamente con le dimensioni.
- Efficienza computazionale: nel caso in cui si debbano elaborare una grande mole di dati, vi sono sicuramente alcune formulazioni che richiedono un tempo di elaborazione più elevato, anche se normalmente si parla in campo ingegneristico dell’ordine dei minuti.
- Distanza dai punti noti: più il punto di cui si vuole stimare il valore si trova vicino a un punto noto, più la differenza fra i vari modelli di interpolazione risulta essere ridotto e quindi è possibile utilizzare un metodo più semplice.
- “Rumore” o disomogeneità fra i dati: è possibile che alcuni dei dati a disposizione (magari avuti da esperimenti o da altre simulazioni) contengano essi stessi degli errori. In questo caso, l’equazione interpolante può avere delle oscillazioni che non sono presenti nell’equazione del fenomeno fisico sottostante. In questo caso, sarebbe meglio non utilizzare il metodo dell’interpolazione (che genera un’equazione passante per tutti i punti noti), ma un metodo approssimante, per esempio, quello dei minimi quadrati, che tende a generare delle equazioni più stabili.
Oltre ai modelli più semplici che si usano nella vita quotidiana, esistono anche formulazioni matematiche più complesse, che posso tenere conto anche di centinaia di parametri differenti. Queste vengono normalmente chiamate superfici surrogate, perché sono appunto delle funzioni che sostituiscono in maniera imperfetta l’analisi reale. La più semplice di queste è ovviamente la regressione polinomiale multivariata, ossia un polinomio composto dalle potenze dei parametri che si vogliono considerare. In caso di domini molti piccoli e dati abbastanza omogenei tra di loro, può essere un metodo che garantisce degli ottimi risultati, ma spesso risulta molto sensibile alle fluttuazioni generati dagli errori nei dati. Inoltre, richiede un numero di dati piuttosto elevato, soprattutto se si vuole tenere conto di tanti parametri.
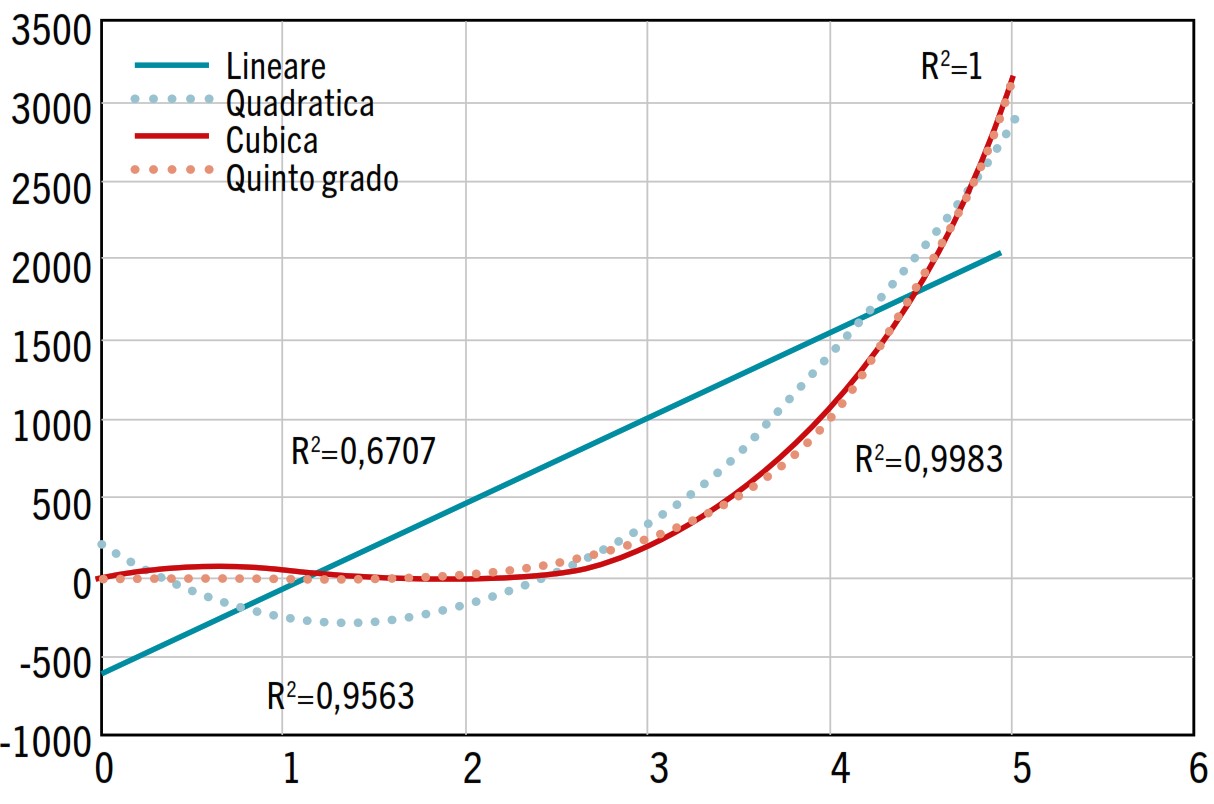
Superficie surrogata di Kriging
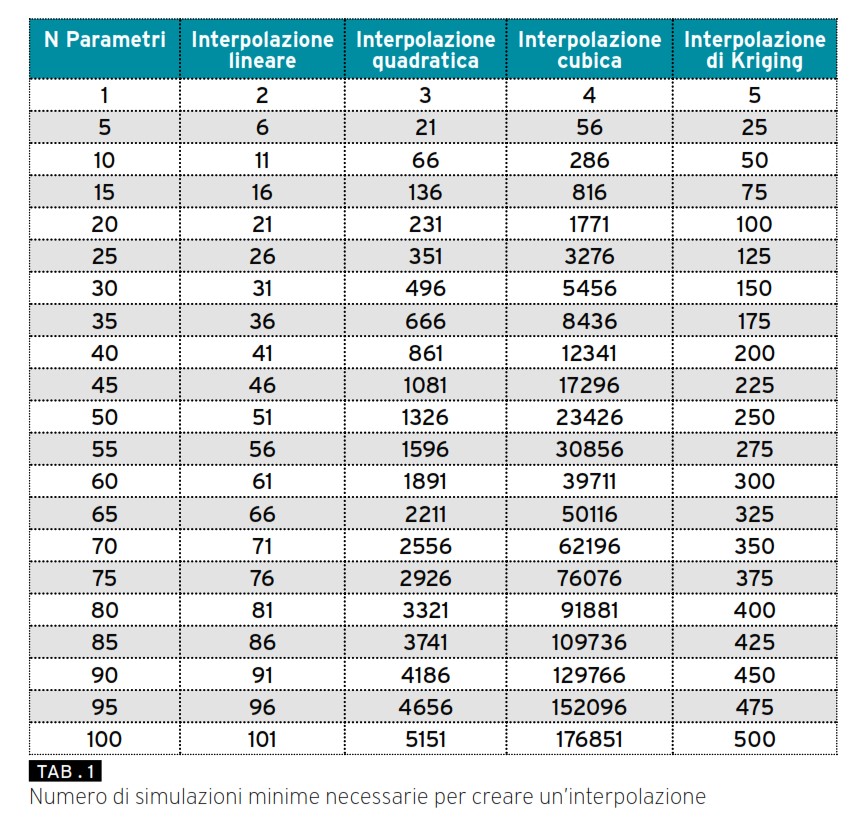
Uno dei modelli che normalmente garantisce i risultati migliori è quello cosidetto di Kriging, ideata dal matematico geostatistico Danie Krige a cavallo degli anni ’50. Uno dei grandi vantaggi di questa formulazione è il ridotto numero di dati necessari per la sua creazione: ne sono necessari soltanto tanti quanti i parametri considerati, anche se è buona norma averne almeno 5 o 10 volte tanti. Se per esempio si vogliono considerare una decina di parametri, (altezza, larghezza, peso, etc..etc..), nel caso si volesse utilizzare un’interpolazione cubica si dovrebbero già possedere almeno 286 simulazioni, che diventano soltanto 50 nel caso di interpolazione di Kriging.
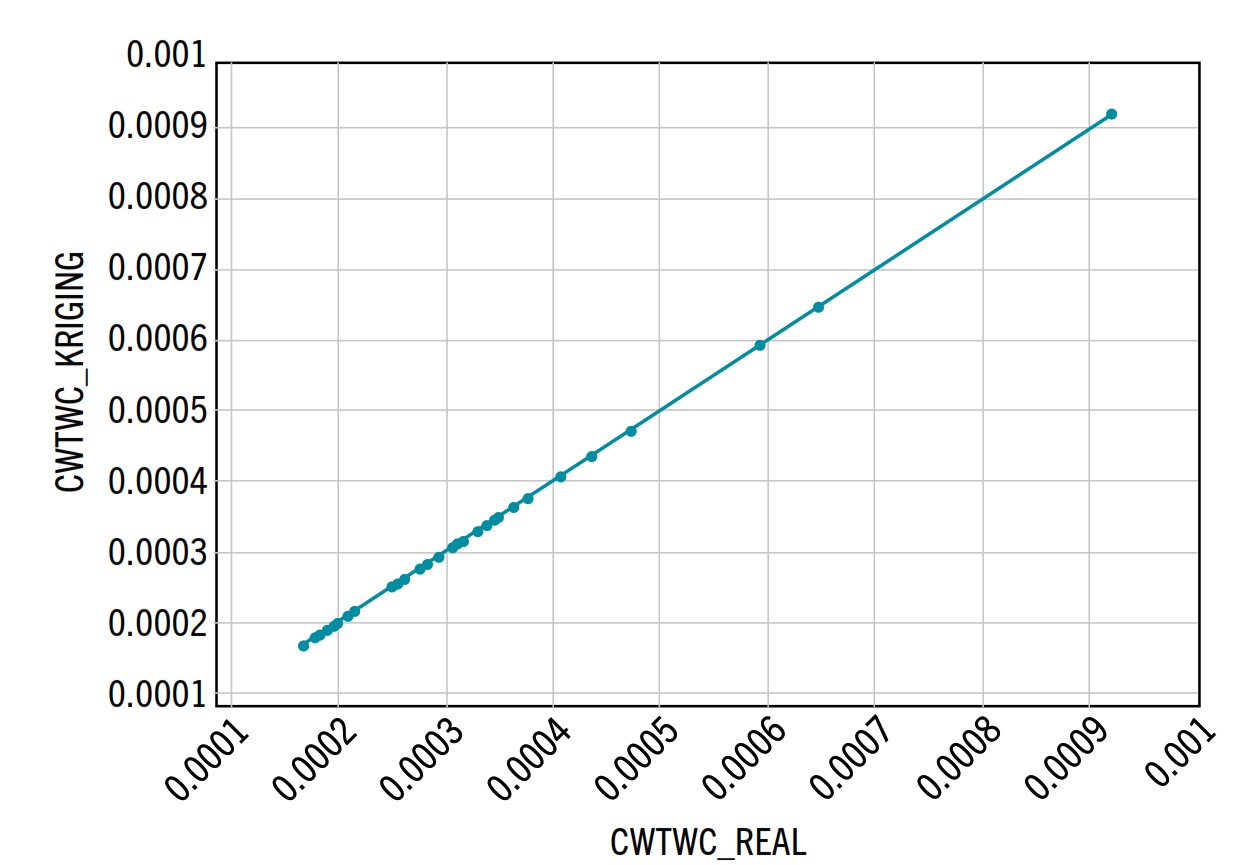
Nel caso in cui si utilizzi un metodo di interpolazione, è comunque buona norma ritestare con una analisi completa le prestazioni della geometria scelta, in quanto, possono esserci anche delle differenze non trascurabili. Ovviamente, i valori di questa nuova analisi posso essere considerati per la creazione di una nuova superficie surrogata che a questo punto potrà fornire dei risultati meno approssimati.
Il grande vantaggio dei metodi basati su superfici interpolanti è quello di offrire al progettista una “black-box” nella quale egli deve soltanto inserire i valori dei parametri di progettazione, senza avere nessuna conoscenza di software di analisi e senza neanche dover disegnare la geometria.
Gli svantaggi sono sicuramente il grande numero di analisi da dovere effettuare per costruire una superficie surrogata che fornisca risultati prossimi a quelli reali e soprattutto il fatto di non poter visualizzare i campi di interesse ( ad esempio, la velocità o la tensione nei vari punti del dominio), perché questo tipo di semplificazione fornisce soltanto valori quantitativi e non qualitativi: può fornire il valore di resistenza al moto, ma non può fornire il campo di velocità attorno all’oggetto, può fornire il valore della tensione massima, ma non il campo di tensione, etc.. etc..
Intelligenza artificiale e Machine Learning
Sia che si utilizzi una superficie surrogata polinomiale che di tipo Kriging, la scelta del tipo di superficie deve essere effettuato a priori e da un essere umano.
Per fortuna, è possibile anche demandare questa scelta a un computer, che attraverso il machine learning (l’apprendimento automatico), è capace di trovare il modello di superficie surrogata che meglio si addice ai dati che si hanno a disposizione.
Inoltre, gli algoritmi di machine learning, al contrario delle superfici surrogate, possono sfruttare dati generati anche da geometrie molto diverse fra di loro. In questo modo, non è necessario effettuare un gran numero di simulazioni prima di avere a disposizione un metodo predittivo. È possibile progettare un’utilitaria utilizzando i dati ottenuti dalle simulazioni di SUV, per esempio.
Questo ci permette di ammortizzare meglio i costi delle simulazioni più complesse e accurate, perché i loro risultati possono essere utilizzati per più progetti.
Inoltre, al contrario delle superfici di risposta, gli algoritmi di machine learning possono anche utilizzare le immagini dei campi di moto o di stress e generare quindi gli stessi campi anche per le geometrie che si vogliono testare. Essi, infatti, ci possono fornire sia dati quantitativi che qualitativi.
D’altro canto, a oggi, non esiste ancora un software di questo tipo che possa essere facilmente collegato a solutori commerciali come Ansys o Starcc+ e la loro implementazione richiede quindi ancora delle grandi conoscenze di informatica.
Inoltre, gli algoritmi utilizzati in ambito ingegneristico sono gli stessi che vengono utilizzati in ambito finanziario o per quanto riguarda le immagini, in ambito cinematografico. Essi quindi utilizzano soltanto il dato grezzo, senza avere alcuna conoscenza della fisica sottostante.
Conclusioni
In questo articolo, abbiamo visto una carrellata di metodi per ottenere dei risultati più o meno affidabili in poco tempo a partire da simulazioni complesse, senza dover per forza essere degli analisti specializzati.
Ovviamente, andrebbe dedicato molto più spazio a ciascuno di loro, facendo anche degli esempi pratici di come possano essere utilizzati in ambito ingegneristico, ma inizialmente è necessario almeno avere coscienza della loro esistenza, per vedere se possono essere utilizzati nella propria azienda.
Infatti, questi metodi possono essere veramente molto utili ai progettisti per avere un’idea delle performance del loro progetto, testare varianti alternative e provare anche ad uscire dalle geometrie più tradizionali, trovandone magari alcune molto più vantaggiose.
D’altro canto, noi analisti non dobbiamo essere spaventati dall’avanzare dell’automatizzazione del nostro lavoro e quindi dal fatto di poter essere soppiantati da un computer. Il lavoro dell’analista, infatti, è soprattutto quello di comprendere se la simulazione ha effettivamente colto la fisica sottostante oltre a quello di suggerire al progettista dove e come modificare il progetto per migliorarne le performance.






